HashMap은 어떻게 구현되어 있을까?
HashMap과 HashTable
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {}
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {}
HashMap과 Hashtable은 둘 다 Map 인터페이스를 구현하는 클래스로, key-value 쌍으로 데이터를 관리한다. 그리고 하나의 key는 하나의 value만 가질 수 있다. HashTable은 JDK 1.0부터 있던 클래스이고 HashMap은 Java 2에서 Java Collections Framework에 속한 클래스로 이 두 클래스는 다음과 같은 차이점이 있다.
- 보조 해시 함수
- HashMap은 보조 해시 함수를 사용하기 때문에 보조 해시 함수를 사용하지 않는 HashTable에 비하여 해시 충돌이 덜 발생할 수 있어 상대적으로 성능상 이점이 있다.
- 동기화
- HashMap의 경우 동기화를 지원하지 않기 때문에 멀티쓰레드 환경에서 안전하지 않다. Hashtable은 동기화를 지원하므로 멀티쓰레드 환경에서 안전하지만 한 번에 하나의 쓰레드만 자원에 접근할 수 있기 때문에 성능 저하가 발생할 수 있다.
HashMap의 내부 구현

HashMap은 내부 배열 버킷(bucket)에 요소를 저장하고 이러한 버킷의 수를 용량(capacity)이라고 한다. 값을 넣을 때 hashCode() 메소드가 반환하는 해시 코드값을 통해 객체가 저장될 버킷의 인덱스를 결정한다. 검색에도 hashCode()를 사용하여 같은 방식으로 버킷을 계산하고 해당 버킷에서 찾은 객체들을 순회하여 equals()를 통해 같은지 다른지 여부를 판단한다.
초기 용량(initialCapacity)
버킷의 초기 용량으로 기본 용량은 16이다. 버킷의 75%가 차면 용량을 2배로 늘리는 과정이 일어난다. 용량이 너무 작으면 해시 충돌이 빈번하게 발생할 수 있고, 너무 크면 메모리 낭비가 발생할 수 있다.
로드 팩터(load factor)
로드팩터는 데이터의 개수/초기 용량 값으로 용량을 언제 재설정 해주어야 효율적인지를 나타낸다. 기본 값은 0.75로 버킷의 75%가 채워지면 용량을 두 배로 늘리는 과정을 시작한다. 로드 팩터를 초과하면 HashMap은 현재 버킷의 수를 두 배로 늘리고, 기존의 모든 엔트리를 새로운 배열에 재배치한다.
- 초기 용량을 작게 설정하면 공간 비용은 절감되지만 데이터가 추가될 때 재할당 빈도가 증가한다.
- 초기 용량을 높게 설정하면 재할당은 줄어들지만 메모리 낭비를 할 수 있다.
Map<String, String> map = new HashMap<>();
map.put("test", "test");
위처럼 map에 put() 메소드를 사용하여 값을 추가할 경우 어떻게 될까?


put()메소드는 새로운 키-값 쌍을 HashMap에 추가하는 역할을 한다. 내부적으로putVal()메소드를 호출하여 실제 저장 과정 수행putVal()은hash()메소드를 호출해 입력된 key 값을 int형 해시값으로 변환한다. 만약 key가 null이면 해시 값은 0으로 설정되고, key가 null이 아니면 해당 key의 Object class에 있는hashcode()를 실행하여 최종 해시 값을 계산한다.- 이렇게 계산된 해시 값을 사용해 버킷 배열에서 저장할 위치가 결정된다.
HashMap은 각각의 key 값에 해시함수를 적용하여 고유한 index를 생성하고, 이 index를 활용해 값을 저장하거나 검색할 때 바로 접근할 수 있으므로 평균 O(1)의 시간복잡도로 데이터를 조회할 수 있다.
해시 버킷 동적 확장
해시 버킷의 개수가 적으면 메모리 사용을 절약할 수 있지만, 해시 충돌이 빈번하게 발생할 수 있다. 그래서 HashMap은 로드 팩터 값에 도달하면 버킷의 수를 동적으로 2배 확장한다. 해시 버킷 개수를 늘리면 해시 충돌로 인한 성능 손실 문제를 어느 정도 해결할 수 있다.
- 해시 버킷 개수의 기본값: 16
- 버킷의 최대 개수: 2^30개
리사이징 시, 새 해시 버킷을 생성하고 기존의 모든 해시 버킷을 순회하여 각 해시 버킷에 있는 Linked List를 순회하며 key-value 쌍을 새로운 버킷에 저장한다. 이 과정에서 해시 버킷 개수가 변경되기 때문에 각 요소의 인덱스 값을 다시 계산하여 적절한 버킷에 저장한다.
해시 분포와 해시 충돌
해시 분포는 해시 함수를 사용하여 데이터들이 버킷 배열의 인덱스에 어떻게 분포되는지를 나타낸다. 해시 함수가 고르게 해시 값을 분포시키면, 데이터들이 버킷 배열에 고르게 분산되어 해시 충돌이 줄어든다. 해시 함수는 가능한 한 많은 해시 값을 생성해 충돌을 최소화 해야한다.
해시 충돌은 서로 다른 두 개의 키가 동일한 해시 값을 가지는 상황으로, 이를 처리하기 위해 개방 주소법(Open Addressing)과 분리 연결법(Separate Chaining)을 사용한다.
개방 주소법(Open Addressing)
개방 주소법은 추가적인 메모리를 사용하는 Chaining 방식과 다르게 비어있는 해시 테이블의 공간을 활용하는 방법이다. 해시 충돌이 발생하면, 버킷 배열 내에서 다른 빈 버킷을 찾아 데이터를 저장한다.
이를 구현하기 위한 대표적인 3가지 방식이 존재한다.
- Linear Probing(선형 탐사) : 해시 충돌이 발생한 경우 다음 버킷이 비어있는 확인하고, 비어 있지 않다면 그 다음 버킷들을 계속 확인하는 방식, 충돌이 발생할 때마다 순차적으로 다음 위치를 확인
- Quadratic Probing(제곱 탐사) : 해시 충돌이 발생한 경우에는 처음에는 한 칸 이동하고 그 다음 계속 충돌이 발생하면 2^2, 3^2 칸씩 옮기는 방식
- Double Hashing(이중 해싱): 해시된 값을 한번 더 해싱하여 새로운 주소를 할당하기 때문에 다른 방법들보다 많은 연산을 하게되지만 균등한 분포를 제공할 수 있다.
Open Addressing은 연속된 공간에 데이터를 저장하기 때문에 Separate Chaining에 비하여 캐시 효율이 높다. 따라서 데이터 개수가 충분히 적다면 Open Addressing이 Separate Chaining보다 더 성능이 좋다. 하지만 배열의 크기가 커질수록(해시 테이블의 용량이 커질수록) 캐시 효율이라는 Open Addressing의 장점은 사라진다. 배열의 크기가 커지면 캐시 적중률(hit ratio)이 낮아지기 때문이다.
분리 연결법(Separate Chaining)
Java HashMap에서 사용하는 방식은 분리 연결법(Separate Chaining)이다. 분리 연결법은 동일한 해시 버킷에 저장된 여러 데이터들을 관리하기 위해 Linked List나 Tree 자료구조를 활용한다. 이 방식은 추가적인 메모리를 사용하여 다음 데이터의 주소를 저장하며, 충돌이 발생했을 때 다음 노드를 연결하는 방식으로 동작한다.
충돌이 빈번하여 리스트 형태로 계속 데이터가 쌓이게 되면 탐색의 시간복잡도가 O(n)으로 나빠진다. 이를 해결하기 위해 Java 8의 HashMap은 리스트의 개수가 8개 이상이 되면 레드-블랙 트리 자료구조를 사용한다.
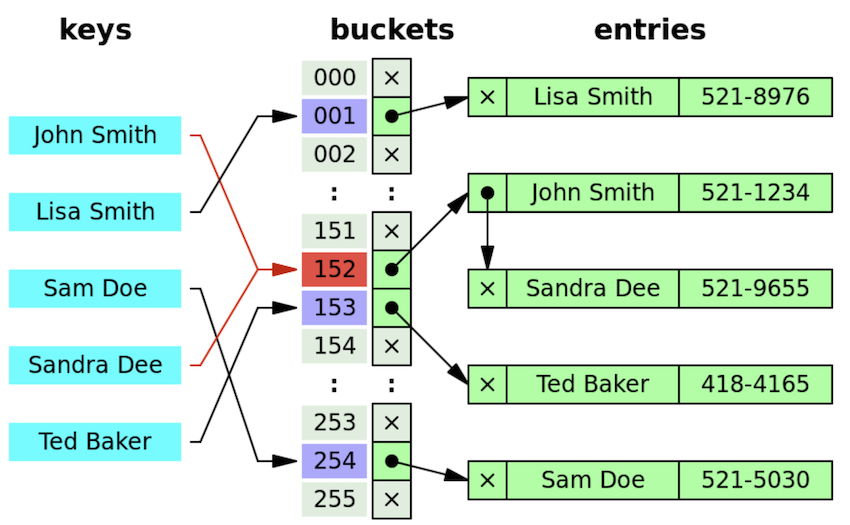
Java 8 HashMap의 Seperate Chaining
Java 7까지는 분리 연결법에서 충돌이 발생하면 Linked List를 이용했다. 하지만 데이터가 많이 쌓였을 때 탐색하는데 시간이 많이 걸린다는 단점이 있기 때문에 Java 8에서는 이러한 단점을 보완하기 위해 리스트를 레드-블랙 트리로 변환하는 방식으로 개선하였다.
- 리스트의 길이가 8개 이상이 되면, 해당 버킷의 리스트를 레드-블랙 트리로 변환하여 탐색 시간을 O(log N)으로 단축시킨다.
- 만약 리스트의 길이가 6개 이하로 줄어들면, 트리는 다시 리스트로 변환된다.

이러한 개선 덕분에 Java 8의 HashMap은 데이터의 양에 따라 효율적인 탐색 성능을 제공할 수 있다.
보조 해시 함수
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
Java 8 HashMap 보조 해시 함수는 key.hashCode()를 호출하여 객체의 해시 코드를 생성 후 해시코드의 상위 16비트 값을 구하고, 상위 16비트와 원래 해시 코드의 하위 16비트를 XOR 연산(^)한다. 이 과정에서 상위 비트와 하위 비트가 섞이게 되어 해시 코드의 분포가 균등해진다.
Java 8의 String 객체에 대한 해시 함수
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
숫자 31을 곱하는 이유는 아래와 같다.
- 31이 소수이기 때문이다.
- 어떤 수에 31을 곱하면 빠르게 계산(성능 향상)할 수 있기 때문이다. 31N = 32N - N인데, 2^5이니 어떤 수에 대한 32를 곱한 값을 shift 연산으로 쉽게 구현할 수 있다. 즉, (N « 5) - N과 같다.
정리
- HashMap은 각각의 key값이 해시 함수에 의해 고유한 index를 가지게 되어 값에 바로 접근할 수 있으므로, 평균 O(1)의 시간복잡도로 데이터를 조회할 수 있다.
- 하지만 해시 충돌이 발생한 경우 Chaining으로 인해 최악의 경우 O(N)까지 시간복잡도가 증가할 수 있다.
- Java의 HashMap은 key-value 쌍 개수가 일정이상이 되면 동적으로 해시 버킷의 크기를 2배로 늘린다. 해시 버킷 개수의 기본값은 16이고 일정개수 이상이 되면 2배씩 증가시켜 최대 2^30개까지 증가시킨다.
- Java HashMap에서는 해시 충돌을 방지하기 위해 Sperate Chaining과 보조 해시 함수를 사용한다.
- Java8부터 데이터의 개수가 일정수준 이상이 되면 Linked List 대신 레드-블랙 트리로 변환하여 검색 성능을 향상시킨다. 해당 버킷에 8개 이상의 key-value 쌍이 쌓일 때 Tree로 변환하며, 다시 6개 이하로 줄어들면 LinkedList로 변환된다.
참고